Description
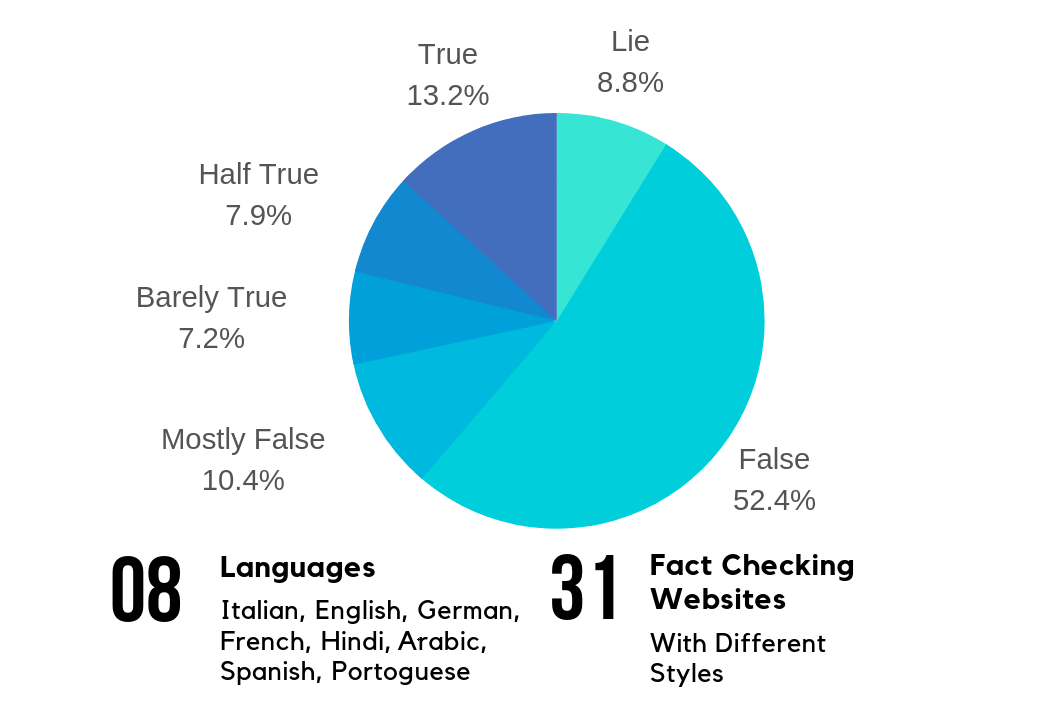
CLERAF (Cross-Lingual Evidence Ranking for Automated Fact-checking) is a dataset that can be used with pre-trained models that have multi-lingual capabilities. It allows for a model that is overall better at generalizing and more robust.
This dataset is consistent with similar datasets that have been used in recent papers, like Politifact and Snopes. In fact, it has six labels that are obtained with the evaluation system introduced by several fact checking websites. The dataset has 15512 text-pairs of claims and articles, as well as the URL used to extract the text, a language code and the publisher.