Description
While researching the state-of-the-art for common NLP tasks like Sentiment Analysis and Stance Detection, in order to realize a pipeline for fact checking, I studied and experimented possible uses of the new breakthroughs in Deep Learning for NLP, with the goal of solving real-world problems.
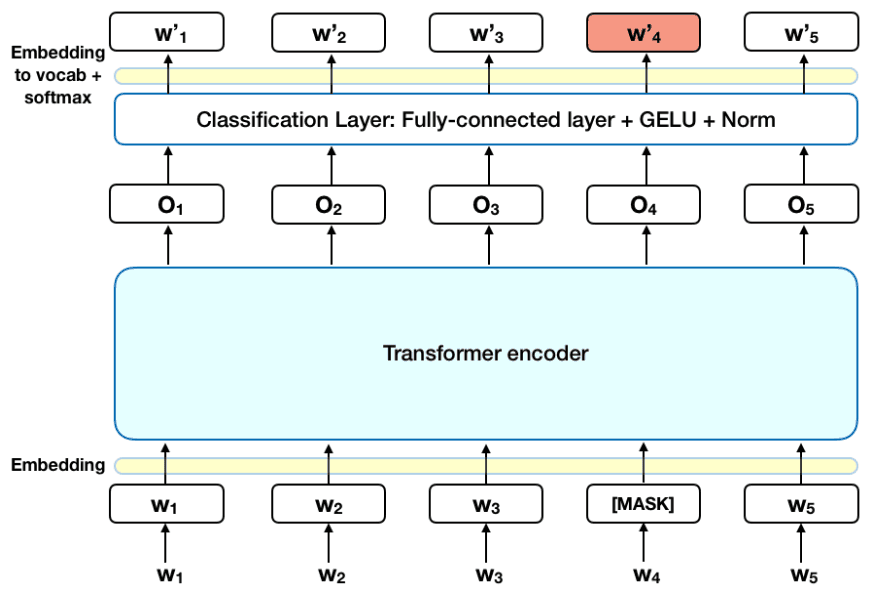
BERT, which architecture is shown in the image, is a great example of that, and in my studies I've tested it with several datasets and setups.
While attempting to find the best model for each pipeline's subtasks, I wrote several Python Notebooks that implement many different embeddings or language models, including: Word2Vec, FastText, InferSent, Universal Sentence Encoder, GPT-2, and ELMo. I also experimented with different architectures like Bi-LSTM, Hierarchical Attention Network and Deep Averaging Network, however, in my experiments, I found out that are the simple models that work best.
This research happened for a period of over one year.